Desafios e oportunidades na proteção de informações na era da IA
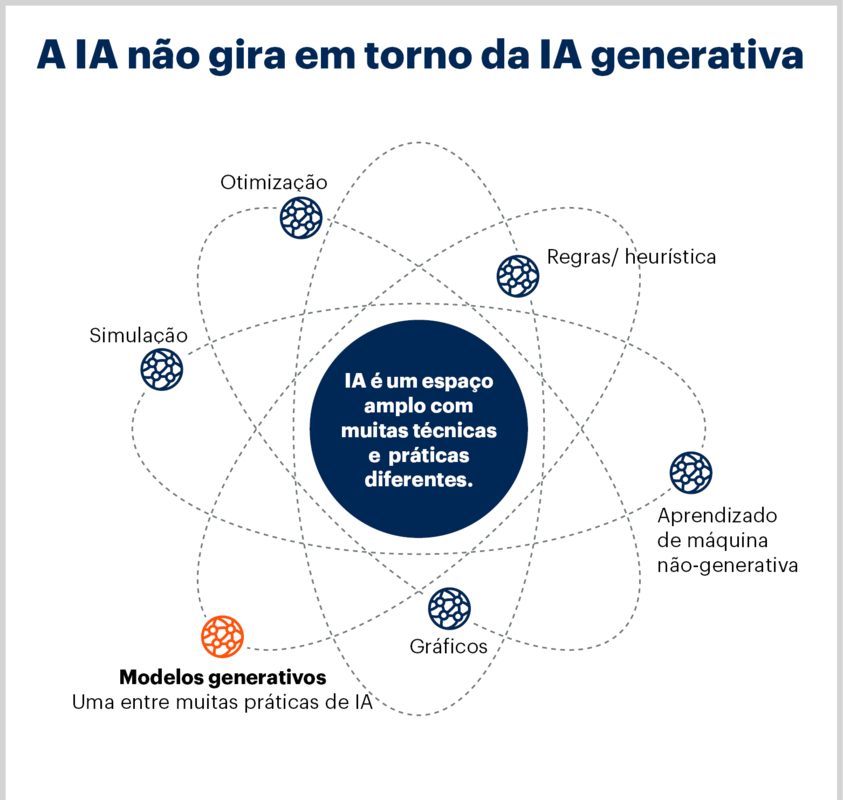
A inteligência artificial (IA) generativa, com sua capacidade de criar conteúdo autônomo e de alta qualidade, está redefinindo os limites da inovação tecnológica. No entanto, essa revolução traz consigo uma série de complexos desafios para a privacidade de dados.
À medida que modelos de IA se tornam mais sofisticados e onipresentes, a questão de como protegemos as informações sensíveis utilizadas em seu treinamento e geradas por eles assume uma importância crítica.
Organizações e indivíduos em todo o mundo enfrentam a tarefa monumental de navegar por um cenário regulatório em constante evolução, onde normas como a Lei Geral de Proteção de Dados (LGPD) e outras legislações globais buscam estabelecer limites e responsabilidades.
Este artigo explora as nuances da privacidade de dados no contexto da IA generativa, delineando os riscos emergentes e as estratégias proativas que as empresas podem adotar para garantir a conformidade e a segurança.
Desde as complexidades das zonas cinzentas regulatórias até a implementação de arquiteturas de proteção por design, examinaremos como é possível não apenas mitigar ameaças, mas também transformar esses desafios em oportunidades para a inovação responsável.

Navegue pelo conteúdo e leia mais sobre como manter a privacidade dos dados com IA:
- A Nova Fronteira da Privacidade: Desafios da IA Generativa
- Limites da LGPD em IA
- Arquitetura de Proteção: modelando privacidade por Design
- Técnicas avançadas de preservação de privacidade
- Frameworks de conformidade
- Papel do DPO em IA generativa
- Estratégias práticas de implementação
- Tendências globais de IA e proteção de dados:
- Dúvidas Frequentes
A nova fronteira da privacidade: desafios da IA Generativa
A proliferação da IA generativa representa uma virada de página na relação entre tecnologia e privacidade. Ao passo que essas ferramentas se tornam capazes de produzir textos, imagens, áudios e até códigos que mimetizam a criatividade humana, surge uma intrínseca necessidade de reavaliar os parâmetros de proteção de dados.
A complexidade não reside apenas na forma como os dados são consumidos e processados pelos modelos, mas também na natureza imprevisível do conteúdo que podem gerar, por vezes revelando, direta ou indiretamente, informações que deveriam permanecer privadas.
Zonas cinzentas regulatórias
O rápido avanço da inteligência artificial generativa tem superado a capacidade de adaptação dos marcos regulatórios existentes, criando um terreno fértil para incertezas jurídicas.
Leis de proteção de dados formuladas antes da popularização massiva da IA, como a LGPD no Brasil e o GDPR na Europa, enfrentam dificuldades em abordar integralmente as especificidades e os novos vetores de risco introduzidos por essa tecnologia. A interpretação e aplicação dessas leis em cenários de IA generativa são frequentemente ambíguas, deixando as empresas em um limbo de conformidade.
Complexidades do consentimento
Um dos pilares fundamentais da privacidade de dados é o consentimento explícito do titular para o tratamento de suas informações. Contudo, em sistemas de IA generativa, a obtenção e gestão desse consentimento se tornam incrivelmente desafiadoras.
Modelos são frequentemente treinados em vastos conjuntos de dados provenientes da internet, que podem incluir informações pessoais coletadas sem um consentimento específico para fins de treinamento de IA.
Como garantir que cada pedaço de dado pessoal que alimenta um modelo generativo tenha sido coletado e utilizado com o consentimento adequado, especialmente quando o uso final dos dados (ou seja, a geração de novos conteúdos) pode não ser totalmente previsível no momento da coleta original?
Além disso, a natureza opaca de alguns modelos de IA, conhecida como “caixa preta”, dificulta a rastreabilidade da origem dos dados e a compreensão exata de como uma informação específica contribuiu para uma saída generalizada.
Isso torna quase impossível para os titulares de dados exercerem seus direitos de acesso, retificação ou exclusão, pois não há clareza sobre quais de seus dados foram processados e como.
As organizações precisam desenvolver mecanismos robustos para gerenciar o ciclo de vida do consentimento de forma dinâmica, que se estenda desde a coleta inicial até o uso no treinamento e na inferência dos modelos de IA, em conformidade com as rigorosas exigências de transparência e finalidade das leis de proteção de dados.
Limites da LGPD em IA
A LGPD, embora abrangente em seu escopo, foi concebida em um período anterior à explosão da IA generativa. A lei enfatiza princípios como a finalidade, a necessidade, a transparência e a segurança dos dados.
No contexto da IA, aplicar esses princípios de forma eficaz é um desafio. Por exemplo, a determinação clara da “finalidade” do tratamento de dados em um modelo generativo que pode ser utilizado para diversas aplicações futuras é complexa.
A “necessidade” de utilizar determinados dados pessoais para o treinamento também pode ser questionada quando alternativas de dados sintéticos ou anonimizados poderiam ser empregadas.
A LGPD também exige medidas de segurança técnicas e administrativas para proteger os dados pessoais de acessos não autorizados e situações acidentais ou ilícitas. Em sistemas de IA, isso implica não apenas a segurança da infraestrutura de dados, mas também a segurança dos próprios modelos contra ataques que visam extrair dados de treinamento ou manipular suas saídas. Outra área de atrito é o direito à explicação sobre decisões automatizadas.
Se um sistema de IA generativa produz conteúdo que afeta um indivíduo, a LGPD pode exigir uma explicação clara sobre como essa saída foi gerada, algo extremamente difícil para modelos complexos e opacos.
Assim, as empresas precisam ir além da mera conformidade superficial, desenvolvendo uma compreensão profunda de como os princípios da LGPD se traduzem em práticas de desenvolvimento e implantação de IA generativa responsável.
Riscos emergentes de vazamento de dados
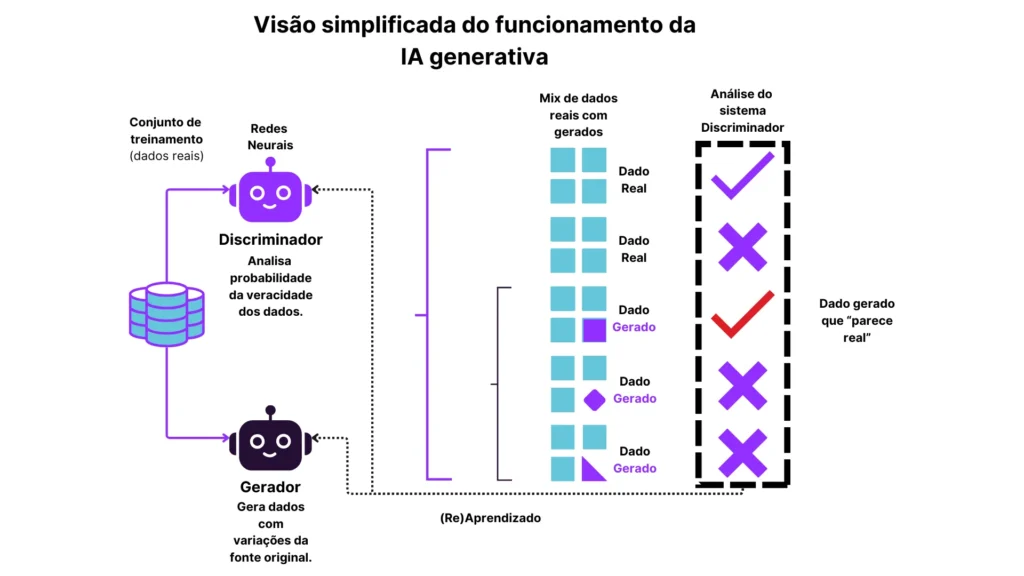
A natureza dos modelos de IA generativa, que aprendem padrões complexos a partir de grandes volumes de dados, intrinsecamente cria novos vetores de risco de vazamento de dados.
Ao contrário dos sistemas tradicionais onde o dado reside em um banco de dados e pode ser protegido por controles de acesso, em IA, o conhecimento sobre os dados é “assado” dentro do próprio modelo. Isso significa que, mesmo sem acesso direto aos dados de treinamento originais, é possível, sob certas condições, inferir ou reconstruir informações sensíveis.
Model inversion attacks
Os model inversion attacks, ou ataques de inversão de modelo, representam uma ameaça particularmente insidiosa para a privacidade em IA. Esses ataques exploram vulnerabilidades em modelos de aprendizado de máquina para reconstruir, parcial ou totalmente, dados de treinamento originais a partir da observação das saídas do modelo.
Em outras palavras, um adversário pode usar a capacidade de um modelo de IA generativa para, de forma reversa, inferir características ou até mesmo identificar indivíduos cujas informações foram usadas para treiná-lo.
Por exemplo, se um modelo foi treinado com imagens faciais, um atacante pode, através de entradas cuidadosamente elaboradas, forçar o modelo a “recriar” rostos específicos do conjunto de treinamento.
Este tipo de ataque é especialmente preocupante em domínios onde os dados de treinamento contêm informações altamente sensíveis, como registros médicos, dados biométricos ou informações financeiras.
Mesmo que as saídas do modelo não sejam explicitamente dados pessoais, a capacidade de inferir atributos ou identidades a partir delas constitui um vazamento de dados significativo e uma violação de privacidade. A complexidade desses ataques exige que as empresas considerem a segurança não apenas nos dados brutos, mas também nos modelos de IA em si, incorporando defesas robustas para mitigar a inferência de informações sensíveis.
Exposição de informações confidenciais
Além dos ataques de inversão de modelo, a própria natureza da IA generativa pode levar à exposição acidental de informações confidenciais. Durante o processo de treinamento, os modelos absorvem e memorizam padrões presentes nos dados.
Se esses dados contêm informações pessoais identificáveis (IPI) ou segredos comerciais que não deveriam ser expostos, o modelo pode, inadvertidamente, “vazá-los” ao gerar novos conteúdos.
Um exemplo notório ocorre quando modelos de linguagem generativa, treinados em vastos corpus de texto, por vezes regurgitam trechos literais de documentos privados ou informações pessoais específicas encontradas em seu conjunto de treinamento. Isso pode acontecer se uma determinada sequência de texto ou um nome foi proeminente o suficiente no conjunto de dados.
Essa “memorização” e subsequente regurgitação de dados sensíveis pode ter consequências graves para a privacidade e a confidencialidade, resultando em multas regulatórias e danos à reputação.
As organizações devem implementar estratégias rigorosas de sanitarização de dados de treinamento, bem como técnicas de monitoramento de saída para identificar e prevenir a exposição de informações confidenciais antes que causem danos.
A vigilância contínua é crucial para garantir que a criatividade da IA generativa não venha acompanhada de um preço inaceitável em termos de segurança e privacidade.
Arquitetura de Proteção: modelando privacidade por Design
A chave para mitigar os desafios da privacidade de dados na IA generativa reside na adoção de uma abordagem proativa e sistemática, conhecida como Privacidade por Design.
Isso significa que as considerações de privacidade e segurança não devem ser um acréscimo posterior, mas sim um componente intrínseco de cada fase do ciclo de vida do desenvolvimento e implantação da IA.
Ao invés de reagir a potenciais vazamentos de dados ou violações de conformidade, as organizações devem arquitetar seus sistemas de IA com a proteção de dados em sua essência, desde o planejamento inicial até a operação contínua. Esta seção detalha as técnicas e os princípios de governança que sustentam essa abordagem.
Técnicas avançadas de preservação de privacidade
Para construir sistemas de IA que sejam inerentemente respeitosos da privacidade, é imperativo empregar técnicas avançadas de preservação de privacidade (PETs).
Essas metodologias vão além da simples anonimização de dados, que muitas vezes pode ser revertida, oferecendo garantias matemáticas ou criptográficas sobre a não exposição de informações sensíveis. A implementação dessas técnicas requer expertise técnica e um compromisso organizacional com a privacidade por design.
Differential privacy
A differential privacy, ou privacidade diferencial, é uma das abordagens mais robustas para proteger a privacidade de dados em análises e modelos de aprendizado de máquina.
Seu princípio fundamental é adicionar ruído aleatório de forma controlada aos dados, de tal maneira que a presença ou ausência de qualquer ponto de dados individual no conjunto de treinamento não afete significativamente a saída final de um algoritmo ou modelo.
Em termos mais técnicos, uma consulta é diferencialmente privada se um observador não consegue determinar se os dados de um indivíduo específico foram incluídos no conjunto de dados, analisando apenas a saída da consulta.
Essa característica oferece uma garantia matemática forte contra ataques de inferência, incluindo os model inversion attacks. Ao treinar um modelo de IA generativa com privacidade diferencial, minimiza-se o risco de que o modelo “memorize” informações específicas de indivíduos, reduzindo a probabilidade de que informações sensíveis sejam regurgitadas ou inferidas.
A implementação da privacidade diferencial pode ser complexa e exige um balanço cuidadoso entre a proteção da privacidade e a utilidade do modelo, pois a adição de ruído pode, em alguns casos, degradar ligeiramente a precisão do modelo. No entanto, é uma ferramenta indispensável para organizações que buscam oferecer garantias de privacidade rigorosas em seus sistemas de IA.
Federated learning
O federated learning, ou aprendizado federado, oferece uma solução inovadora para treinar modelos de IA sem a necessidade de centralizar os dados de treinamento.
Em vez de mover os dados para um servidor central para o treinamento, o aprendizado federado permite que os modelos sejam treinados localmente nos dispositivos ou servidores dos usuários, mantendo os dados sensíveis em suas fontes origionais.
Apenas as atualizações do modelo (ou seja, os pesos e vieses ajustados) são compartilhadas com um servidor central, onde são agregadas para criar um modelo global melhorado.
Este paradigma de treinamento distribuído tem implicações profundas para a privacidade de dados, especialmente na IA generativa. Ele mitiga significativamente o risco de vazamento de dados que ocorreria se todos os dados fossem coletados em um único repositório.
Ao manter os dados locais, as empresas podem respeitar as diretrizes de privacidade e conformidade, como a LGPD, que impõem restrições à movimentação e armazenamento de dados pessoais.
O aprendizado federado é particularmente valioso em cenários onde os dados são altamente sensíveis ou regulamentados, como na saúde ou finanças, permitindo que a IA generativa seja desenvolvida com base em dados do mundo real sem comprometer a confidencialidade dos indivíduos. A combinação de aprendizado federado com outras técnicas como a privacidade diferencial pode criar um ambiente ainda mais seguro para o desenvolvimento de modelos de IA.
Criptografia homomórfica
A criptografia homomórfica é uma tecnologia revolucionária que permite realizar computações diretamente em dados criptografados, sem a necessidade de descriptografá-los primeiro.
Isso significa que as operações de treinamento e inferência de modelos de IA podem ser executadas em dados criptografados, e o resultado da computação também permanece criptografado. Apenas o proprietário da chave de descriptografia pode acessar o resultado em sua forma original, protegendo a privacidade dos dados durante todo o processo de computação.
Para a IA generativa, a criptografia homomórfica oferece o mais alto nível de proteção de dados. Ela permite que modelos sejam treinados em dados fornecidos por múltiplas partes, garantindo que nenhuma das partes (nem mesmo o provedor do serviço de IA) tenha acesso aos dados brutos das outras.
Isso é crucial para cenários onde a colaboração é necessária, mas a privacidade é primordial. Embora a criptografia homomórfica ainda esteja em um estágio de desenvolvimento que a torna computacionalmente intensiva e, portanto, mais lenta do que as operações em texto simples, seu potencial para habilitar uma nova era de IA privada e segura é imenso.
À medida que as capacidades computacionais avançam, espera-se que essa tecnologia se torne uma ferramenta fundamental para garantir a confidencialidade dos dados em sistemas de IA generativa.
Leia mais em: O que é e como funciona a AI Max no Google Ads?
Frameworks de conformidade
A implementação de frameworks de conformidade específicos para IA é crucial para garantir que as organizações operem dentro dos limites legais e éticos. Esses frameworks devem integrar as exigências de leis como a LGPD, GDPR, CCPA, entre outras, com as peculiaridades do ciclo de vida da IA generativa. Um framework eficaz deve abranger:
- Avaliação de Impacto sobre a proteção de dados (DPIA) para IA: realizar DPIAs regulares e aprofundadas para identificar e mitigar **riscos de privacidade** antes da implantação de qualquer modelo de **IA generativa**.
- Princípios de IA responsável: incorporar princípios como transparência, explicabilidade, equidade e responsabilidade no desenvolvimento e uso da IA.
- Gestão do ciclo de vida do dado: definir políticas claras para coleta, armazenamento, processamento, compartilhamento e descarte de dados utilizados por sistemas de IA, garantindo que a qualidade e a privacidade dos dados sejam mantidas em todas as etapas.
- Auditorias e monitoramento contínuo: estabelecer mecanismos para auditar os modelos de IA, monitorar seu desempenho e detectar quaisquer desvios que possam levar a vazamentos de dado* ou resultados viesados.
- Resposta a incidentes: desenvolver planos de resposta a incidentes de **segurança e privacidade** específicos para a IA, garantindo uma ação rápida e eficaz em caso de violação.
A construção desses frameworks exige uma colaboração multifuncional, envolvendo equipes jurídicas, de segurança, de engenharia e de negócios, para criar um ecossistema de conformidade que seja tanto abrangente quanto adaptável às inovações rápidas da IA generativa.
Papel do DPO em IA generativa
O Data Protection Officer (DPO), ou Encarregado de Dados, já desempenha um papel central na garantia da conformidade com a LGPD e outras regulamentações de proteção de dados.
No contexto da IA generativa, a importância do DPO é amplificada, e suas responsabilidades se tornam ainda mais complexas e estratégicas. O DPO atua como um ponto de contato essencial entre a organização, os titulares de dados e as autoridades reguladoras, e deve possuir um profundo entendimento tanto da legislação de proteção de dados quanto das nuances técnicas da IA.
As responsabilidades do **DPO em IA generativa** incluem:
Aconselhamento sobre conformidade: Fornecer orientação especializada sobre como a LGPD e outras leis se aplicam ao desenvolvimento, treinamento e implantação de sistemas de IA generativa.
Monitoramento da conformidade: Supervisionar a implementação das políticas internas e garantir que as operações de IA estejam em conformidade com as regulamentações de proteção de dados.
Gestão de DPIA: Liderar ou apoiar a realização de Avaliações de Impacto sobre a Proteção de Dados para projetos de IA, identificando e avaliando os riscos de privacidade.
Ponto de contato para titulares de dados: Facilitar o exercício dos direitos dos titulares de dados (acesso, retificação, exclusão, etc.) em relação aos dados tratados por sistemas de IA.
Ponto de contato para autoridades: Atuar como interlocutor principal com as autoridades de **proteção de dados** em questões relacionadas à IA.
Sensibilização e treinamento: Promover uma cultura de privacidade e segurança dentro da organização, educando equipes sobre as melhores práticas no uso da IA.
O DPO deve estar ativamente envolvido desde as fases iniciais de design de projetos de IA generativa, garantindo que as considerações de privacidade por design sejam incorporadas desde o início. Sua expertise é fundamental para transformar os desafios regulatórios em oportunidades para construir confiança e responsabilidade na era da IA.
Estratégias práticas de implementação
Compreender os desafios e as técnicas avançadas é o primeiro passo. O próximo é traduzir esse conhecimento em ações concretas e estratégias práticas de implementação que possam ser aplicadas no dia a dia das operações com IA generativa.
A implementação eficaz da privacidade de dados requer uma abordagem multifacetada que combine políticas internas claras, treinamento contínuo e a adoção de ferramentas e metodologias de mitigação de riscos. Esta seção detalha como as organizações podem colocar a privacidade por design em prática, criando um ambiente seguro e conforme para a inovação com IA.
Construção de Políticas Internas
A fundação de qualquer programa de proteção de dados robusto reside em políticas internas bem definidas.
No contexto da IA generativa, essas políticas devem ser abrangentes, claras e adaptadas às especificidades da tecnologia, orientando o comportamento de todas as partes envolvidas no desenvolvimento, uso e gestão de sistemas de IA. Elas servem como um guia para a tomada de decisões, assegurando que as considerações de privacidade e segurança sejam intrínsecas a todas as operações.
Diretrizes e uso de IA
É imperativo que as organizações estabeleçam diretrizes de uso de IA que enderecem explicitamente as questões de privacidade e segurança de dados. Estas diretrizes devem cobrir uma série de aspectos, incluindo, mas não se limitando a:
- Classificação de dados: estabelecer um sistema claro para classificar os dados (públicos, internos, confidenciais, pessoais sensíveis) e definir quais categorias podem ser usadas para treinar ou interagir com modelos de IA generativa. Proibir estritamente o uso de dados pessoais sensíveis ou confidenciais sem consentimento explícito e medidas de proteção adicionais.
- Anonimização e pseudonimização: definir os requisitos e métodos aprovados para anonimizar ou pseudonimizar dados pessoais antes de serem utilizados em modelos de IA, garantindo que as técnicas sejam robustas e resilientes a ataques de reidentificação.
- Gestão de entradas e saídas: estabelecer regras claras sobre quais tipos de informações podem ser inseridas em modelos de IA generativa (evitando dados proprietários ou sensíveis) e como as saídas geradas devem ser verificadas para garantir que não contenham informações confidenciais ou enviesadas.
- Responsabilidades: atribuir responsabilidades claras para o gerenciamento de dados de IA, incluindo a curadoria de conjuntos de dados de treinamento, a monitorização do desempenho do modelo e a resposta a incidentes.
- Uso ético: incorporar princípios éticos, como fairness (justiça), transparência e responsabilidade, garantindo que os sistemas de IA não perpetuam preconceitos ou causem danos injustos.
- Revisão e aprovação: exigir um processo de revisão e aprovação para o desenvolvimento e implantação de novos sistemas de IA generativa, garantindo que todas as considerações de privacidade e segurança sejam abordadas antes da entrada em produção.
Essas diretrizes devem ser dinâmicas, revisadas e atualizadas regularmente para se adaptar à evolução da tecnologia de IA e às mudanças no cenário regulatório, garantindo que permaneçam relevantes e eficazes.
Tendências globais de IA e proteção de dados:
Diversas tendências globais indicam que a regulamentação da IA se tornará mais rigorosa e específica, especialmente no que tange à privacidade e ética. Estar ciente dessas tendências permite que as organizações ajustem suas estratégias de proteção de dados antes que novas leis entram em vigor.
IA Act da União Europeia: Este é um dos marcos mais ambiciosos, propondo uma abordagem baseada em risco para a regulamentação da IA, classificando sistemas em categorias de risco inaceitável, alto, limitado e mínimo.
Sistemas de IA generativa provavelmente cairão sob a categoria de risco limitado ou alto, dependendo de sua aplicação, com requisitos específicos de transparência, supervisão humana e avaliação de risco. A UE também enfatiza a necessidade de rótulos de dados para informar os usuários que o conteúdo foi gerado por IA.
Novas regulamentações nos EUA: Embora não haja uma lei federal abrangente de IA nos EUA, diversos estados estão explorando legislações, e o governo federal tem emitido ordens executivas e diretrizes focadas na segurança, privacidade e responsabilidade da IA.
A Federal Trade Commission (FTC) e outras agências têm expressado preocupações com vieses algorítmicos e práticas enganosas em IA.
Regulamentação no Reino Unido: O Reino Unido está desenvolvendo sua própria abordagem regulatória para IA, com foco em princípios como segurança, transparência e responsabilidade, buscando um equilíbrio entre inovação e proteção.
Expansão da LGPD e Leis Similares: Muitos países estão seguindo o exemplo do GDPR e da LGPD, implementando suas próprias leis de proteção de dados ou fortalecendo as existentes. Essas leis provavelmente serão adaptadas ou terão diretrizes específicas emitidas para abordar o tratamento de dados por sistemas de IA.
Foco na explicabilidade e transparência: Há uma crescente demanda por modelos de IA que sejam mais transparentes e explicáveis, permitindo que os usuários compreendam como as decisões são tomadas ou como o conteúdo é gerado. Isso se alinha com o direito à explicação presente em muitas leis de proteção de dados.
IA Responsável e Ética: Governos e organizações internacionais estão cada vez mais desenvolvendo princípios e frameworks para a IA responsável e ética, que transcendem a mera conformidade legal e buscam alinhar o desenvolvimento da IA com valores humanos fundamentais.
Monitorar essas tendências globais permite que as organizações identifiquem os vetores de mudança regulatória, preparem suas infraestruturas e políticas, e colaborem proativamente com reguladores e formuladores de políticas para moldar um futuro mais seguro para a IA.
O caminho da inteligência responsável
A era da IA generativa está aqui para ficar, prometendo transformações sem precedentes em todas as esferas da sociedade.
Contudo, o verdadeiro valor dessa revolução tecnológica só será plenamente realizado se for construída sobre uma base sólida de confiança, privacidade e responsabilidade. A navegação segura neste novo cenário exige um compromisso inabalável com a **proteção de dados, integrando a privacidade por design em cada etapa do ciclo de vida da IA.
À medida que nos preparamos para cenários regulatórios futuros, com tendências globais apontando para uma governança de IA mais rigorosa, a capacidade de antecipar mudanças legislativas se torna uma vantagem estratégica.
As empresas que abraçam o caminho da inteligência responsável não apenas cumprem a LGPD e outras leis, mas também constroem sistemas de IA que são seguros, justos e dignos da confiança de usuários e da sociedade.
O futuro da IA generativa é promissor, mas seu sucesso duradouro depende intrinsecamente de nossa capacidade de priorizar a privacidade de dados e construir um ecossistema digital onde a inovação e a proteção coexistam harmoniosamente.
Dúvidas Frequentes sobre Inteligência Generativa e privacidade de dados:
Que tipo de dados a IA Generativa usa para o treinamento e isso representa um risco?
As IAs generativas são tipicamente treinadas em grandes volumes de dados (textos, imagens, vídeos, etc.), muitas vezes coletados da internet. Inevitavelmente, parte desses dados contém informações confidenciais ou dados pessoais (como informações de saúde, financeiras, dados de redes sociais ou dados biométricos).
O risco reside na possibilidade de o modelo “memorizar” e exfiltrar (revelar) dados confidenciais contidos no dataset de treinamento, ou de usar inputs confidenciais de um usuário para treinar modelos futuros sem transparência ou consentimento adequado.
Posso inserir dados confidenciais (como informações da empresa ou clientes) em um chat de IA Generativa?
Não é recomendado inserir dados sensíveis, pessoais, estratégicos ou internos em ferramentas de IA Generativa baseadas em nuvem, especialmente aquelas sem políticas internas de segurança e governança claras.
Existe um alto risco de vazamento acidental ou de que essas informações sejam usadas para o aprimoramento do modelo, expondo dados que deveriam ser privados ou secretos.
Os dados que insiro são armazenados? Se sim, por quanto tempo e onde?
A opacidade do processamento de informações é uma grande preocupação. Em muitas ferramentas baseadas em nuvem, não há garantias claras sobre onde os dados são armazenados, por quanto tempo ou se são excluídos de forma segura.
A falta de transparência sobre o destino dos dados (transferência internacional, por exemplo) pode gerar problemas de conformidade legal.
Web Stories: