Engenharia de contexto é quando a gente cria sistemas que decidem quais informações um modelo de IA vai ver antes de dar uma resposta.
A Inteligência Artificial (IA) tem evoluído de um mero processador de dados para um parceiro cognitivo em diversas esferas, do ambiente corporativo à pesquisa científica.
No entanto, a transição de um Modelo de Linguagem Grande (LLM) de propósito geral para uma entidade capaz de fornecer respostas confiáveis, factuais e contextualmente relevantes é o maior desafio atual. Essa transição é orquestrada por uma disciplina emergente e crucial: a Engenharia de Contexto.
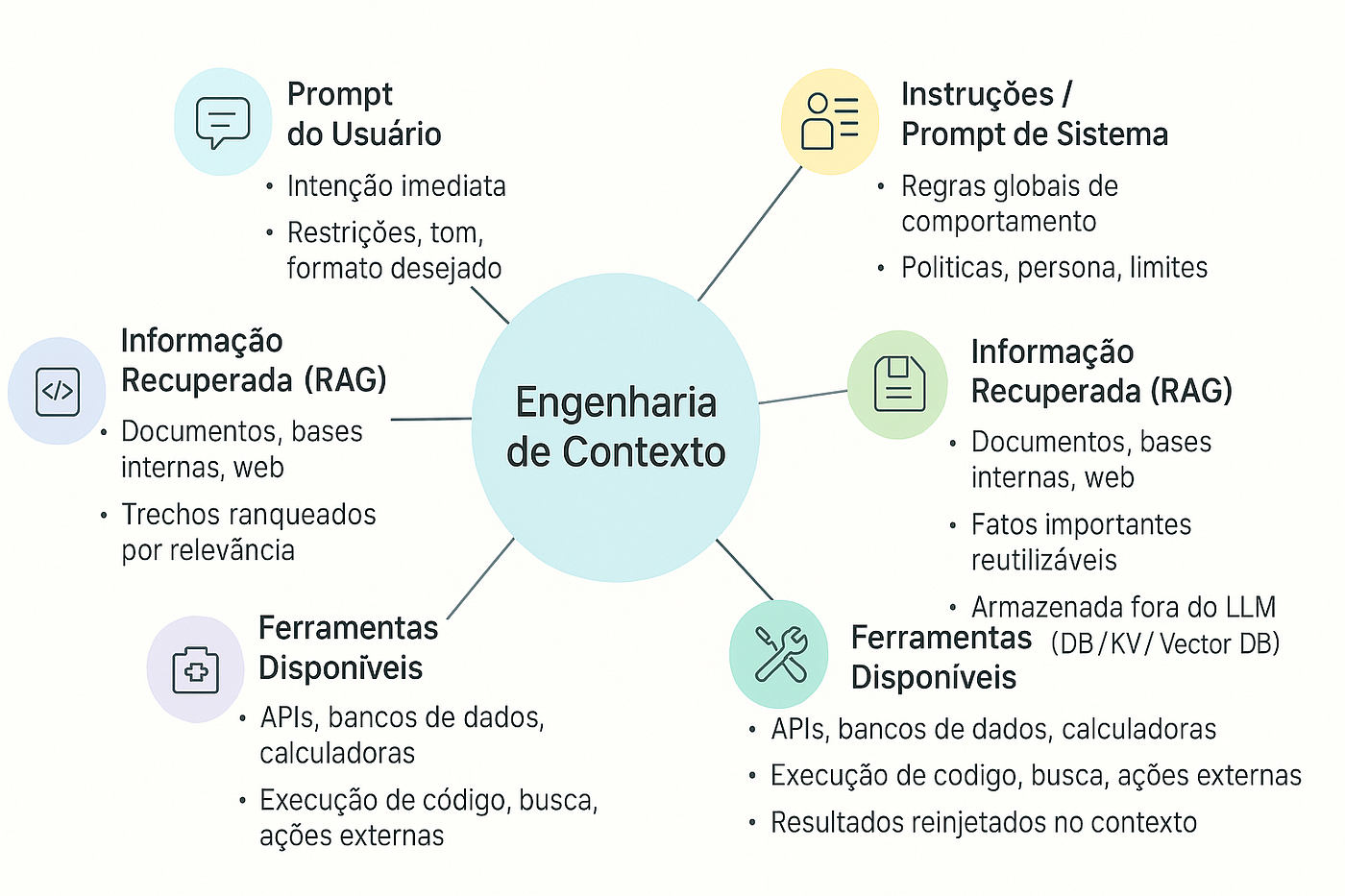
Longe de ser um mero truque de prompt, a Engenharia de Contexto é a ciência e a arte de estruturar, curar e apresentar o ecossistema informacional de uma IA.
É o mecanismo que garante que o modelo não dependa apenas do seu treinamento estático (que pode ser desatualizado ou genérico), mas sim opere com uma base de conhecimento dinâmica, proprietária e verificável no momento exato da interação.
Este artigo visa desmistificar a Engenharia de Contexto em seu sentido mais amplo, explorando os seus fundamentos conceituais, a complexidade arquitetônica do RAG (Retrieval Augmented Generation) e sua importância irrefutável para a confiabilidade e acurácia da IA moderna. Entender essa disciplina é fundamental para qualquer profissional que busque maximizar o potencial da IA de forma segura e ética.

Navegue pelo conteúdo e leia mais sobre Engenharia de Contexto:
O que é a Engenharia de contexto?
A Engenharia de Contexto é a disciplina que abrange o conjunto de metodologias e arquiteturas destinadas a expandir o input de um Modelo de Linguagem Grande (LLM) com informações externas e relevantes.
Sua função primordial é garantir a confiabilidade e a acurácia factual da saída da IA. Ela transcende a manipulação da instrução (prompt) para focar na manipulação do conhecimento acessível ao modelo durante a inferência.
Em termos práticos, um LLM é uma máquina probabilística, treinada para prever a próxima palavra com base em padrões massivos de texto. Sem contexto, ele pode ser um excelente imitador de linguagem, mas um pobre consultor factual.
A Engenharia de Contexto introduz um paradigma de ancoragem, onde a resposta gerada é vinculada a uma fonte de verdade externa e verificável.
Contexto na IA
Os LLMs são treinados em datasets gigantescos, mas seu conhecimento é estático (congelado no tempo do treinamento) e genérico. Para ser útil em um domínio especializado (medicina, direito, engenharia), a IA precisa de conhecimento específico:
- Específico do Domínio: Normas ABNT, precedentes jurídicos, protocolos clínicos.
- Proprietário/Restrito: Dados internos de uma empresa, histórico de clientes, documentos confidenciais.
- Temporalmente Crítico: Últimos relatórios financeiros, flutuações de mercado em tempo real.
O contexto resolve essa lacuna epistemológica, fornecendo a profundidade e a especificidade do conhecimento que faltam ao modelo base.
Do Few-Shot Learning ao Design de Contexto
A Engenharia de Contexto é a culminação de várias técnicas de fornecimento de contexto:
- Zero-Shot Learning: O modelo responde sem exemplos prévios, apenas com base na instrução.
- Few-Shot Learning: Pequenos exemplos (exemplars) são incluídos no prompt para “ensinar” o modelo o formato e o estilo da resposta desejada.
- In-Context Learning (ICL): A IA aprende a performar uma tarefa específica (como tradução ou sumarização) simplesmente através das instruções e exemplos fornecidos na janela de contexto do prompt, sem a necessidade de retreinamento (fine-tuning).
A Engenharia de Contexto de hoje (Design de Contexto) eleva o ICL ao máximo, utilizando arquiteturas avançadas como o RAG para injetar não apenas exemplos de formato, mas sim grandes volumes de informação factual e referencial diretamente no contexto do prompt, tornando a janela de contexto a principal fonte de conhecimento para a inferência.
O que é Retrieval Augmented Generation (RAG)
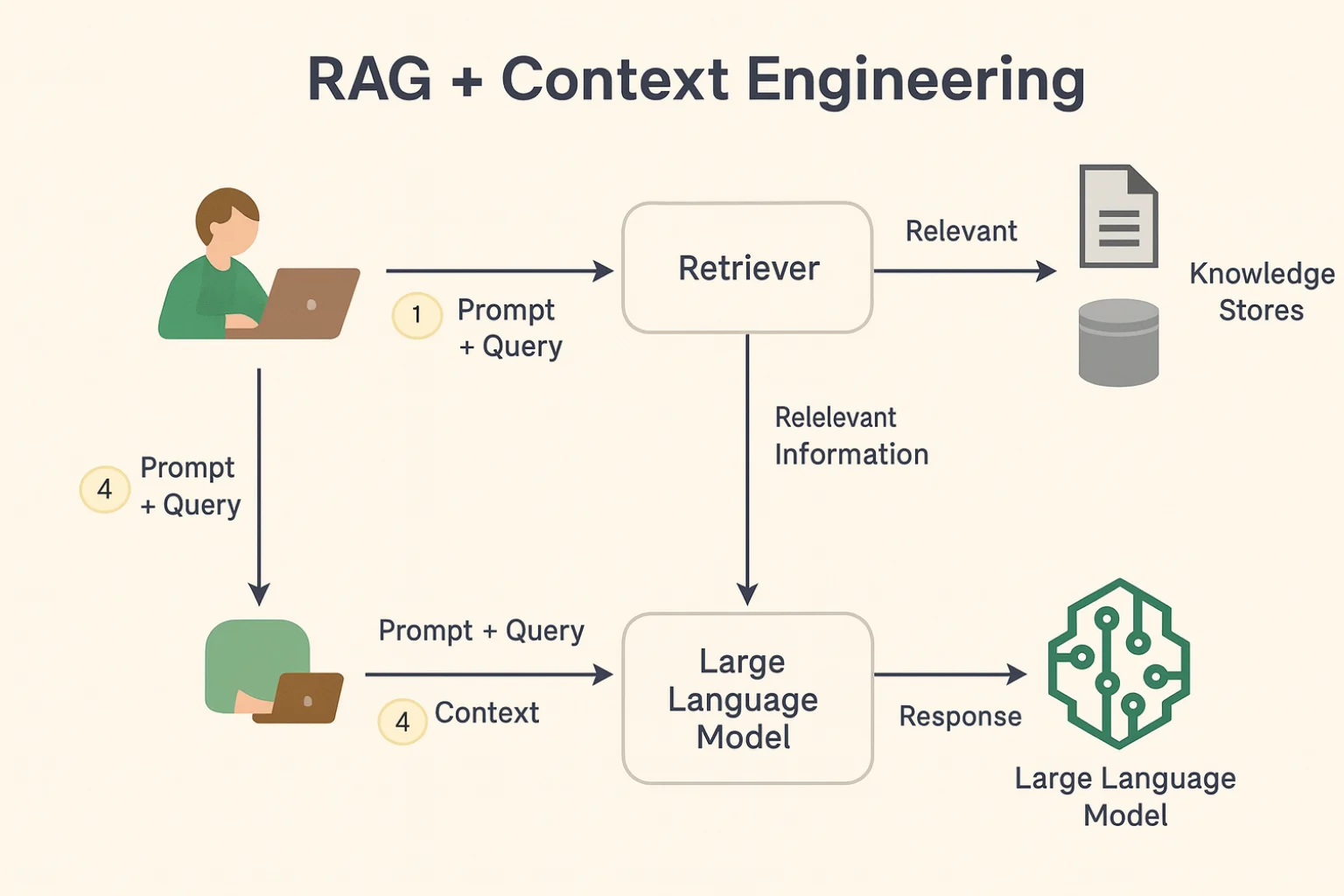
A Retrieval Augmented Generation (RAG) é a infraestrutura dominante para a Engenharia de Contexto, pois permite a manipulação eficiente de vastas bases de conhecimento externas.
O sucesso do RAG depende da articulação de três componentes técnicos: a vetorização, o banco de vetores e o fluxo de recuperação.
Para que o contexto seja buscável, o LLM precisa entender o significado dos dados, não apenas as palavras-chave. Isso é feito através dos modelos de embedding:
- Pré-Processamento (Chunking): Documentos brutos e extensos são divididos em fragmentos (chunks) de tamanho ideal. Um chunk deve ser grande o suficiente para conter contexto útil e pequeno o suficiente para ser processado eficientemente e caber na janela de contexto do LLM.
- Vetorização: Cada chunk é processado por um Modelo de Embedding, que o transforma em um vetor de números (um embedding). Este vetor captura a semântica (o significado) do texto. Textos com significados semelhantes terão vetores geometricamente próximos no espaço vetorial.
A escolha do modelo de embedding é crítica, pois a qualidade do embedding determina a precisão da recuperação do contexto (o quão bem o sistema encontra o chunk certo).
A Função Crítica dos Bancos de Vetores (Vector Databases)
O Banco de Vetores é o coração do RAG. Ele é um tipo de banco de dados otimizado para o armazenamento, indexação e busca de vetores de alta dimensionalidade.
- Busca de Similaridade: Em vez de usar SQL para buscar por correspondência exata, o Banco de Vetores usa algoritmos de vizinhos mais próximos aproximados (ANN – Approximate Nearest Neighbors) para encontrar os vetores (e, portanto, os chunks de texto) que estão mais próximos semanticamente do vetor da consulta do usuário.
- Escalabilidade: Os Bancos de Vetores são projetados para gerenciar e buscar eficientemente em bases de conhecimento que podem conter bilhões de chunks, garantindo que a recuperação de contexto ocorra em milissegundos, fundamental para aplicações em tempo real.
- Exemplos: Pinecone, Weaviate, Milvus, Qdrant.
O Fluxo de recuperação e aumento do Prompt
O processo de inferência RAG combina a busca de contexto com a geração de texto:
- Transformação da Consulta: A pergunta do usuário é vetorizada pelo mesmo modelo de embedding usado para os chunks.
- Recuperação: O vetor da consulta é enviado ao Banco de Vetores para buscar os K chunks mais relevantes semanticamente.
- Aumento (Augmentation): Os chunks recuperados são combinados com o prompt original (instrução e pergunta) em uma única entrada. Esta entrada, agora rica em contexto factual, é enviada ao LLM.
- Geração com Ancoragem: O LLM gera a resposta, utilizando o contexto aumentado como sua fonte primária de informação, minimizando a dependência de seu conhecimento interno, genérico ou desatualizado.
Estratégias de Design e Governança de Contexto
A Engenharia de Contexto em nível profissional vai além da simples conexão RAG; ela envolve o design cuidadoso das fontes, a governança de dados e a orquestração de múltiplas camadas de informação.
Um contexto robusto é uma combinação de diferentes tipos de informação:
| Camada de Contexto | Função e Exemplo |
| Referencial | Informação factual estática: Manuais, políticas internas, leis, artigos científicos. |
| Histórico/Conversacional | Diálogos anteriores, estado atual da conversa,histórico de decisões. Garante coerência e continuidade. |
| Ambiental/Dinâmico | Dados em tempo real: Notícias, cotações de ações, localização, clima. Garante relevância temporal. |
| Identidade/Sistêmica | Perfil do usuário, permissões, metadados dos chunks. Adapta o tom e filtra o conteúdo. |
A Curadoria exige um ciclo contínuo de limpeza, validação e atualização dos dados. Chunks mal definidos ou informações contraditórias na base de conhecimento podem levar a resultados pobres, mesmo com a melhor arquitetura RAG.
Engenharia de Dados
A eficácia do RAG começa na Engenharia de Dados.
Estratégias de Chunking Otimizadas: O chunking não pode ser aleatório. Técnicas avançadas consideram a estrutura lógica (cabeçalhos de seção, parágrafos), o tamanho da janela de contexto e a coesão semântica para dividir o texto.
Metadados Enriquecidos: A indexação de metadados junto aos vetores é crucial. Metadados podem incluir a data do documento, o autor ou o nível de confidencialidade. Durante a recuperação, os metadados podem ser usados para filtrar os chunks antes da busca de similaridade (ex: “Buscar apenas documentos não confidenciais criados após 2024″), aumentando a precisão e a segurança.
Orquestração de Pipelines: A criação de pipelines robustos de ETL (Extração, Transformação e Carga) para manter os dados no Banco de Vetores sincronizados com as fontes de dados primárias da organização (CRMs, ERPs, etc.).
Gerenciando o Risco Informacional
O uso de dados proprietários para contextualização introduz sérias preocupações de Governança de Dados.
- Controle de Acesso (RBAC): É imperativo implementar o Role-Based Access Control (RBAC) no nível do Banco de Vetores, garantindo que a IA, ao interagir com um usuário específico, só possa recuperar chunks de documentos aos quais esse usuário tem permissão de acesso.
- Segurança e Confidencialidade: O modelo de RAG, por manter os dados proprietários fora do LLM (que pode ser um modelo de API de terceiros), já oferece uma vantagem de segurança.
Contudo, é vital garantir que o tráfego de dados para o LLM não contenha informações de identificação pessoal (PII) que possam ser processadas ou armazenadas pelo provedor do modelo.
- Vieses Contextuais: A curadoria deve ativamente identificar e mitigar vieses presentes nos documentos de referência, pois o LLM replicará o viés se o contexto o contiver.
O Contexto como Solução para os Desafios da IA
As alucinações não são um erro de codificação, mas uma falha intrínseca à natureza probabilística do LLM. O modelo prioriza a fluidez linguística sobre a fidelidade factual.
A Engenharia de Contexto transforma a dinâmica:
- Substituição de Memória: O RAG substitui a memória estática e probabilística do LLM por uma memória externa, factual e consultável.
- Força da Referência: O prompt aumentado atua como uma instrução coercitiva, indicando ao modelo: “Use APENAS as informações a seguir para responder.”
Essa ancoragem factual pode aumentar a acurácia factual das respostas em até 70% em domínios ricos em dados, como evidenciado em benchmarks especializados (MMLU, DROP).
Otimização de Custos e Escalabilidade
A Engenharia de Contexto via RAG é economicamente superior ao Fine-Tuning (Ajuste Fino):
- Menor Custo de Treinamento: O Fine-Tuning é um processo caro, demorado e exige grandes volumes de dados rotulados e retreinamento completo a cada atualização do conhecimento.
- Manutenção Eficiente: O RAG permite a atualização do conhecimento empresarial em tempo real, exigindo apenas a vetorização e indexação dos novos chunks, o que é significativamente mais rápido e barato.
- Otimização de Tokens: A Engenharia de Contexto também pode ser usada para resumir o contexto recuperado antes de enviá-lo ao LLM, reduzindo o número de tokens de entrada e, consequentemente, o custo da API de inferência (que é cobrada por token).
A Engenharia de Contexto é fundamental para sistemas que exigem precisão e personalização:
- Sistemas Jurídicos: Contextualização com jurisprudência, estatutos e históricos de casos específicos.
- Medicina: Diagnóstico assistido por contexto que inclui prontuários, diretrizes clínicas atuais e artigos científicos mais recentes.
- Assistentes de Codificação: Injeção de documentação de API, bases de código existentes e padrões de estilo da empresa para gerar código funcional e alinhado aos padrões da organização.
- Simulação e Educação: Criação de ambientes de aprendizado que respondem com base em vastos repositórios de conhecimento verificável (contexto referencial).
Tendências e o Futuro da Inteligência Contextual
O futuro da Engenharia de Contexto é a construção de sistemas de IA que percebem e raciocinam com a mesma complexidade do ambiente humano.
O RAG está evoluindo para lidar com dados não textuais:
- Contexto Visual: Vetorização de imagens, vídeos e gráficos. Um prompt sobre um “defeito em um produto” pode desencadear a recuperação de embeddings de imagens de defeitos conhecidos, além de manuais de texto.
- Contexto de Áudio: Uso de transcrições e análise semântica de áudio para contextualizar chamadas de serviço ou interações em tempo real.
Essa multimodalidade permite uma compreensão mais rica e abrangente do mundo real.
A próxima geração de RAG será dinâmica:
- Adaptive Context Window: A capacidade de um sistema RAG determinar, em tempo real, que a consulta é complexa e exige a busca de um volume maior de chunks ou a consulta a múltiplas fontes de dados sequencialmente (Multi-Hop RAG).
- Continuous RAG: Mecanismos de feedback onde as respostas bem-sucedidas ou o novo conhecimento validado são automaticamente reindexados (vetorizados) e adicionados à base de conhecimento, criando um ciclo de aprendizado contínuo sem a necessidade de retreinamento completo do LLM.
A Engenharia de contexto como prática para empresas
A Engenharia de Contexto não é apenas uma evolução técnica; é a metodologia central que transforma a promessa da Inteligência Artificial em uma realidade de negócios confiável e factual.
Ela garante que os sistemas de IA operem com precisão cirúrgica, eliminando o risco de alucinações e maximizando a utilidade dos dados proprietários. Em um cenário onde a informação é o ativo mais valioso, a capacidade de contextualizar a IA é o diferencial estratégico que separa líderes de seguidores.
Neste cenário de inovação acelerada, a Tupiniquim se posiciona na vanguarda, não apenas utilizando, mas dominando as tecnologias de contextualização de ponta.
Compreendemos que a verdadeira inteligência reside na conexão eficiente entre o poder de processamento do LLM e a especificidade do seu conhecimento.
Perguntas Frequentes (FAQs)
1. O que significa "Engenharia de Contexto" em termos simples?
É a prática de fornecer à Inteligência Artificial (LLMs) informações externas e específicas (como documentos, manuais, histórico de conversas) no momento da interação, para garantir que suas respostas sejam precisas, relevantes e não baseadas em invenções (alucinações).
2. Por que a Engenharia de Contexto é mais importante que o Prompt Engineering?
O Prompt Engineering otimiza a pergunta, enquanto a Engenharia de Contexto expande a base de conhecimento da IA. Para tarefas que exigem fatos específicos ou conhecimento atualizado (o que é comum no mundo real), otimizar a pergunta não basta; é preciso garantir que o conhecimento correto esteja presente.
3. O que é um Banco de Vetores e por que ele é essencial para o Contexto?
Um Banco de Vetores (Vector Database) armazena as representações numéricas (embeddings) do seu conhecimento. Ele é essencial porque permite que a IA busque rapidamente os trechos de texto que são semanticamente mais parecidos com a pergunta do usuário, e não apenas por palavras-chave, o que é a base da recuperação de contexto do RAG.
4. Como a Engenharia de Contexto lida com a privacidade dos dados?
Ela lida com a privacidade através de Governança de Dados. Os dados sensíveis permanecem sob o controle do usuário (na base de conhecimento da empresa). O sistema RAG é configurado para aplicar filtros de acesso e anonimização, garantindo que o LLM só receba o contexto permitido e necessário para a resposta, sem expor dados confidenciais inadvertidamente.
Web Stories: